From Chaos to Calm – Vulnerability Management for a Dynamic, Sprawling Technology Estate

Felix
Thanks to the organizers for giving us the opportunity to speak on this topic. If anyone’s feeling hung over or not quite there or feeling sick just note that the nearest exit may be behind you.
Quick introduction: my name is Felix, I’m a Principal Consultant at Thoughtworks. If you’ve never heard of Thoughtworks: We’re a technology consultancy and we’re basically putting together strategy design and software engineering into bespoke solutions for clients that solve interest problems. I’m an engineer by trade, I’ve spent many moons in the infosec space and I’ve led the Thoughtworks Cyber Security team for some of that time.
Nazneen
Hi everyone, I’m Nazneen! I’ve been with Thoughtworks for 12 years, currently spearheading the threat assessment and security engineering stream of work within the Infosec department. Prior to this within the security domain, I have have led and set up the app sec program for Thoughtworks internal operations – that was the talk I gave last year. So I’m really excited to be here.
Felix
All right so today we’re going to talk about the challenges imposed onto a vulnerability management program by the sheer scale and rate of change of a technology estate we’re going to relive some key decisions and and lessons learned on our journey to building a vulnerability management program and building a robust scalable and automated security framework to actually improve your security posture. We’re going to talk about vast technology estates and how that changes how one might approach this. We’re going to talk about how autonomous teams come into here and the competing priorities that they might have and the challenges that this imposes when you’re actually to make them do something.

Nazneen
Coming from a developer background vulnerability management has been quite new but a fascinating journey for me. It has been eye openening to see how quickly new vulnerabilities emerge and challenge our best efforts to secure our systems but before I delve into the challenges let’s get a quick sense of the room.
How many of you all here are either subjected to contributing to or even leading vulnerability management efforts? Could you raise your hands?
Okay thank you.
Felix
Keep them up, keep them up. For those that that have them up keep them up yeah please keep your hands up.
Nazneen
For all the hands that are up: How many of you all believe that the program is tackling the right problems and creating a sign significant positive impact towards your company?
That’s amazing, for the folks who still have their hands up we would love to exchange notes and hear about your approaches too. Feel free to put your hands down, thank you very much.
For the rest of the folks who are unsure of all the alerts coming your way or are here to understand how to enhance your vulnerability management program or are even yet to embark on this journey, we believe this talk will bring a different perspective to this topic when we share the Technologies and the efforts that underpinned this transformation we underwent.
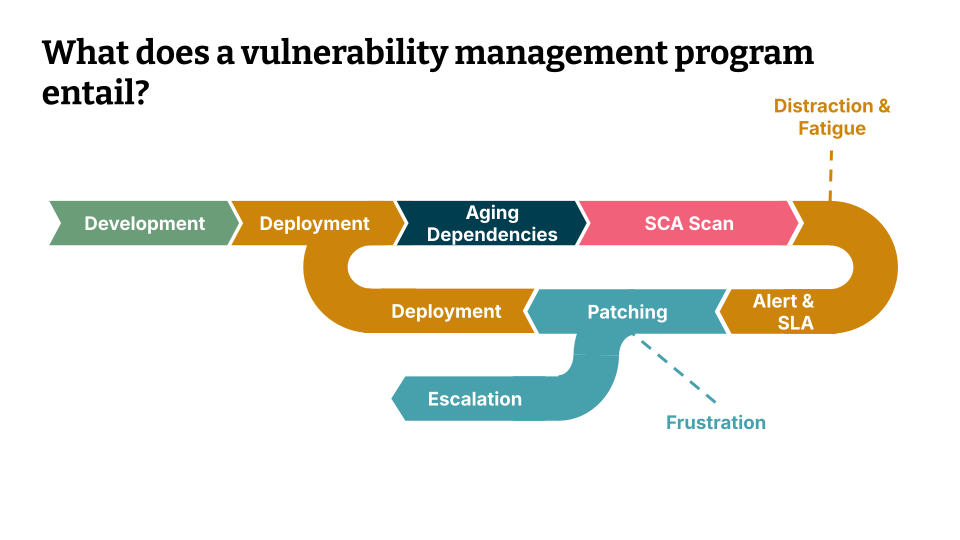
So with that let’s start by understanding what a vulnerability management program entails.
Usually the responses people hear or read is:
- “it’s this program is all about fixing security holes”
- “it’s about patching”
- “it’s about a tool that runs in an automated fashion to detect vulnerabilities or detect issues”
So overall it’s about continuous assessment, scanning, and remediation and, yeah, that’s quite concise, that quite sums it up.
So let’s look at the life cycle so usually a product is developed, it’s deployed, then there is a scanner that looks at vulnerabilities in dependencies. So it scans a lock file or an agent scans a host, then there could be a ticket or there will be a ticket that is generated if there is a critical or high severity vulnerability. Then an alert is sent to the team with a pre-defined time to state: “this is the period in which you should fix this vulnerability”
So there’s a lot of effort in this in this process and the question that keeps coming back is: Despite all these efforts, is the security posture changing in a meaningful manner? In fact, developers frown upon this because the number of overwhelming alerts that come their way without business context is difficult to shift through. And at the same time Security Consultants who for a very good reason view the weakest link as a potential breach find the continuous followups quite mundane and repetitive. So overall there’s a lot of ambiguity, a lot of frustration, a lot of blame game, a lot of confusion on what to do.
So let’s base our conversations on some data.
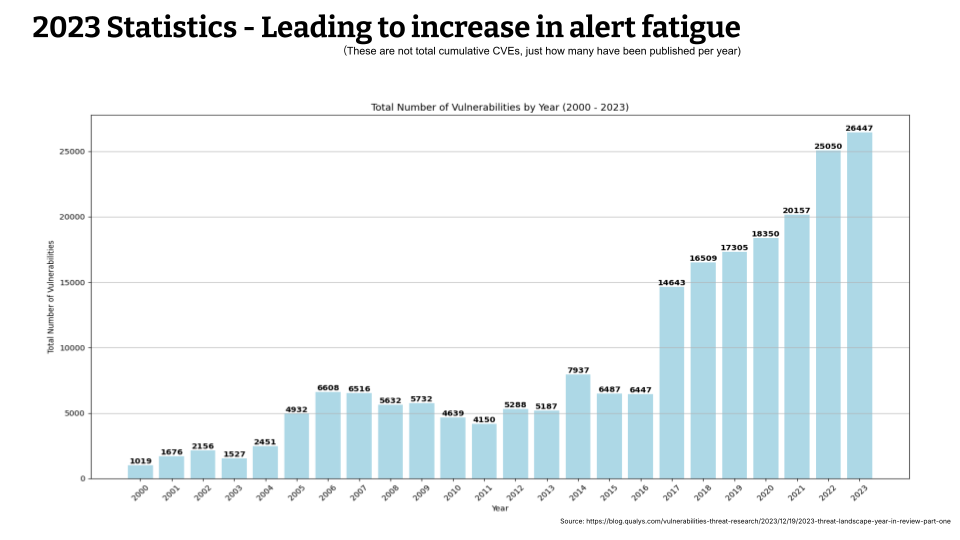
Don’t worry about the tiny numbers, I’ll speak to it, but just let your eyes go out of focus and look at the shape of the graph. This is talking about the number of vulnerabilities that were disclosed per year. In 2023 about 26,000 vulnerabilities were disclosed. It surpasses the number by 1,500 in 2022. So every year there are more vulnerabilities. So despite these numbers of vulnerabilities, CSPM tools also generate a number of alerts for misconfigurations, away from your best practices or regulatory compliance. That is also generating a lot for your team. So the number of vulnerabilities disclosed are sending alerts to your team, as well as cspm tools are generating alerts. So a lot of alerts are coming towards your team!

So apart from the number of alerts that are increasing the number of breaches are also high. Despite all the security tooling the number of breaches are at an all-time high. Let’s take 5 Seconds to read through this data. The number or the data that stands out the most is the cost of a data breach. At the same time if you see 80% of the organizations have faced an incident due to cloud misconfiguration. Previously as I was saying cspm tools generate a number of alerts and it’s quite possible that actual attackable flows in the cloud infrastructure get lost because of the flurry of alerts. To me this data or the persistent High number of breaches calls out that there is some inefficacy in the current alerting, detection and remediation systems. If we are not going to make a change we are going to face a lot of consequences.

In fact, the breaches have caused a number of enterprises a fortune and here is an incomplete sample of a few. The links to these breaches are listed towards the end of the deck.
- https://www.theverge.com/2017/7/12/15962520/verizon-nice-systems-data-breach-exposes-millions-customer-records
- https://www.businessinsider.com/deep-root-analytics-sued-after-data-breach-2017-6
- https://www.msspalert.com/news/wwe-database-leak-more-than-3-million-users-exposed
- https://www.virsec.com/resources/blog/fedex-data-breach
- https://www.veeam.com/blog/veeam-data-incident-resolved.html
- https://wpblog.com/godaddy-data-breach-on-amazon-s3/
- https://edition.cnn.com/2019/07/29/business/capital-one-data-breach/index.html
- https://techcrunch.com/2019/01/29/rubrik-data-leak/
- https://cybersecurityventures.com/honda-leaks-database-with-134-million-rows-of-employee-computer-data/
- https://lifelock.norton.com/learn/data-breaches/microsoft-exposed-250-million-customer-records
- https://threatpost.com/fingerprints-of-1m-exposed-in-public-biometrics-database/147345/
- https://www.privacyend.com/biggest-data-breaches/
- https://www.dclsearch.com/blog/2020/02/estee-lauder-hit-with-huge-data-breach
- https://www.itpro.com/data-insights/big-data/360525/data-breach-exposes-details-on-millions-of-us-seniors
- https://cybersrcc.com/2021/06/21/audi-volkswagen-customer-data-leak/
- https://www.secureblink.com/cyber-security-news/artwork-archive-in-data-breach-after-discovery-of-misconfigured-aws-s3-bucket-leaked-421-gb-of-data-affecting-7k-customers
- https://www.datenschutz-notizen.de/massive-leak-of-personal-data-at-scraping-company-socialark-2428967/
- https://iwantleverage.com/security/microsoft-power-apps-misconfiguration/
- https://www.stealthlabs.com/news/flexbooker-suffers-massive-data-breach-millions-of-users-compromised/
- https://www.twingate.com/blog/tips/AWS-data-breach
- https://www.skyhighsecurity.com/industry-perspectives/bluebleed-leak-proves-it-again-you-cannot-assume-cloud-service-providers-are-secure.html
- https://techcrunch.com/2022/10/27/amazon-prime-video-server-exposed/
- https://www.theregister.com/2020/07/21/twilio_javascript_sdk_code_injection/
- https://www.theregister.com/2023/05/08/in_brief_security/
- https://www.theregister.com/2023/04/18/capita_breach_gets_worse/
- https://www.bleepingcomputer.com/news/security/us-no-fly-list-shared-on-a-hacking-forum-government-investigating/
- https://www.wired.com/story/diksha-india-education-app-data-exposure/
- https://www.bleepingcomputer.com/news/security/us-no-fly-list-shared-on-a-hacking-forum-government-investigating/
- https://www.websiteplanet.com/news/fiatusdt-leak-report/

For reference, overall, this is how Qualis sums up this issue: “If everything is critical, nothing is.”
And the report from Qualis states that out of all the disclosed vulnerabilities only 1% was related to a significant high risk and was exploited in the wild. Only 1%.

So let’s sum up our observations that led to the transformation:
- The barrage of alerts towards the development teams has led to alert fatigue and made the teams insensitive to real threats.
- Not all severities are created equally. It is very difficult to gauge the severity of vulnerabilities without business context. You may be happy to talk to a team to say that there’s an sshd vulnerability because it has remote code execution, but that’s on a container that is short lived, running a trivial management report, as well as on a container that does not have any ports open to the internet. Is that really critical in that case? Is the likelihood high?
- We ended up using a ticketing system that suited the tech security team. It was not helpful for the delivery teams, which increased the communication barriers.
- The number of tools we used which were very specialized for their security scanning created a fragmented view.
There was no way to stitch up the alerts, there was no one view to understand where action is required. In fact, a lack of a single pane of glass also created an issue for the security analyst. The manual follow-ups when your operations are scaling is impractical. You cannot work with a spreadsheet or Excel sheet to say:
- Who’s the infra owner?
- Is this team disbanded?
- If this team is disbanded, who do we escalate to?
It is not going to scale with scaling operations. Towards the end you will not end up looking at the real threats. While working on an sshd with remote code execution on a short-lived container, a cookie is exposed that will exfiltrate your data, which was missed because our tools don’t catch such kind of issues. So the traditional methodology of looking at number of vulnerabilities as a metric did not work for us and we found it ineffective. So something had to change and that is where I hand it over to Felix to talk about the how.
Felix
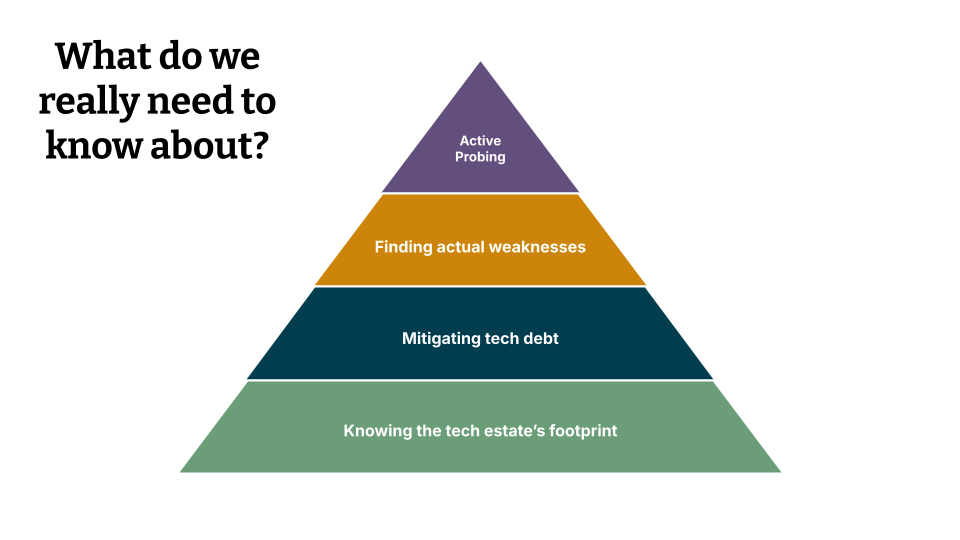
Thank you very much so what do we really need to know about in order to build an effective vulnerability management program? All right, let’s start with knowing the technology estate’s footprint: you need to know the kind of things that you should be defending. You need to figure out a way to mitigate security debt or tech debt. there is no real difference between those two, and I’m going to use those two expressions interchangeably. Then you need to figure out out of all the things that could potentially go wrong and which ones actually present a problem to you, and then no vulnerability management effort is complete without going on the offensive and really poking at your systems and finding the hidden problems that only really present themselves when someone’s actively looking at them.

Let’s talk about the footprint of the technology estate. So I had an embarrassing moment a while back so my CISO approached me and he said: “I have this report from an external company – they had no knowledge of our internal systems – and they found a pretty big hole in our systems.” It was nothing critical for the business but still it was some exploitable hole and he was like: “Can you comment on that?” – I really couldn’t because I was looking through our systems and we didn’t even scan that thing. So the big lesson here is please avoid opportunistic scanning! We ran into this problem because we put our scanners where it was easy to put our scanners. We had them in pipelines, we scanned some containers, we scanned some hosts, but there were a ton of hosts that we just didn’t know about, so we didn’t actually bother scanning them. We never looked there.
Opportunistic scanning is a problem for you, so you might ask: How do I actually get a view of my tech estate? How is that possible? Most in this room, you’re engineers, you’re going to have an inside out view of your tech estate, which means you know where things are. You have all the knowledge of the tech estate, but the problem is you don’t have the attacker’s tools. So you have all the knowledge, none of the tools, and none of the priority of which things actually matter. Then there is an outside-in view of your tech estate, which is an attacker’s view. They have no knowledge of where things, are they have all the tools to look for things, but they also have no prioritization. And then there’s a third view you can adopt in order to look at your tech estate, which is existing threat models, which means go to your risk management department adopt a business level view on things. Your risk management department likely have threat models, they likely have business level risks, they have no knowledge about the tech of course, they have no knowledge about attacker’s tools and attacker’s views on their systems, but they have all the priority, all the things that that matter to them if they break. So let yourself be inspired by these views and then gauge the you can gauge the extent of your technology estate through questions.

So in order to reach your robust understanding here’s things that you could ask yourself:
- How do systems in my technology estate interact amongst themselves?
- How do I reach across the boundaries of my tech estate?
- How are my employees connecting? Is there a VPN or something?
- How is how are systems networked?
- Where are my computer sources?
- Where is my data storage?
- Where is my data processing?
- Is there some form of structure that is underlying my tech estate?
- Are there physical assets?
- Are there non-computer assets in the tech state that I need to know about?
- Is there OT technology like manufacturing robots or pipeline sensors or that sort of thing?
- Is there IoT type of things? Like the Raspberry Pi that controls your meeting room and stuff like that..
So those are questions that you can inquire into and in the end you probably going to have a list of things like IP addresses, VPCs, DNS records, etc. all the way down to switches and sensors. Those are all things that you that you will have to include if you want to build an actual vulnerability management program for your company.

So just be aware you’re probably going to miss some things. It’s not the end of the world, just let your mind be open you’re not going to catch everything, you’re not going to be looking at everything. So be humble here.
All right, if you’re in the cloud it’s quite easy to discover the the assets that you have via an API. If you’re on-prem, it’s slightly harder. Because you will have to discover from records, some Excel sheet or some manually written down thing where someone has actually noted the subnets are or where the switches are or passwords for the switches or that sort of thing.
Also be aware that if your technology is state is large enough it will probably shift below your feet while you’re standing on this. So you have to automate to avoid that drift. If your scanners are actually reaching into systems just be aware that there is new systems coming online and old systems shutting down, so you will have to have sort of self-enrollment and self-provisioning that has to happen automatically. You will have to have some form of of drift correction. Maybe someone is deleting a note is deleting a role from an AWS account that you rely on in order to actually assume-role into that AWS account. So, self-healing, drift correction, auto-enrollment, and auto-provisioning are super important, yet you will still have to do things manually.
There will always be these five remaining percent where you actually have to follow up on your own. Write playbooks for them because in order to also keep bus-factor low in your team, write down what you’re actually doing. Set yourself alerts and reminders that you have to do these things.
All right at this point we know how big our tech estate is, we know all the things that we should be scanning, so let’s talk about mitigating tech debt.

The first problem that you’re going to have is you’re going to have a lot of scanners out there probably. You have to kind of take their data and and put it together. I really recommend avoiding 10 different tools competing for your attention, so take the data put it together in some place in a common format to make sense of this. But the problem is that these findings alone without context don’t mean a lot. So you have to enrich them, you have to give them context. If you present a developer with a finding and say “Hey, we found an RCE on this host” and you just give them the host identifier, they’re going to be like “cool, which AWS account? which region? which VPC? where is this thing? how do I find this?” So you don’t want to create more work for the teams downstream. Enrichment in general helps highlighting the things that matter and it helps speed up fixing. You could use low code tools like Tines, for example. We generally prefer AWS Step Functions just because it’s a very nice way to break down an enrichment pipeline for findings. It’s very very useful in that regard.
A problem that is often overlooked but is super critical is: “How do I know who actually needs to fix this? How do I infer ownership?” So you need to have some form of register about who owns what in your company. Who owns AWS accounts? Who owns switches? Who’s responsible for an office? Who’s responsible for hosts? That sort of thing … so you need to create some kind of register it has to be up to date. But the more critical thing is it has to be kept up to date. And it has to be machine readable because if you’re going to go around and design ownership by hand you’re just going to kill yourself with work. Unassigned risk in such a thing is just worse than useless because you’ve done all the work but you’re still not getting anything done and as I said manual followup is just going to kill you.
So … we have a finding, we’ve enriched it, we know who should fix it, now we have to assign it to them. We have to notify them somehow. Here it’s super important to keep in mind that this is a friendly process! You don’t want to be the security team that goes around and says: “This is shit! That is shit!” That’s not how it works. You want to be inviting the teams to collaboratively fix security issues in their in their systems, so notify them in a friendly manner. Maybe notify them a second time in a friendly Manner and then if there is an escalation process it’s still a friendly process right. It doesn’t help if you just become unfriendly.
This is slightly hindered by the fact that a lot of companies have something like “You have 72 hours to fix high and critical vulnerabilities!”. That’s a complete anti-pattern. In fact, in their minimum viable security product, MVSP, Google went away from this “You have seven days to fix something” and they basically said you have 30 days to apply a patch and 90 days to develop a patch. It’s a very different approach to how most companies handle vulnerabilities internally. The problem with this 72 or 24 or 48 hour or however short SLA is that if there is a potential problem, this is way too short for the team to actually prioritize this in their workflow and actually get this done. And it’s way too long for other reasons that I’ll get into later, so you’re stuck between 72 hours bein way too long and way too short at the same time. Just keep it relevant for them what you’re notifying them on.
Next thing, you have to track remediation. This is actually something that is not spoken enough about, because if you have a vulnerability, it represents risk. Risk has four different general ways to deal with it:
- You can avoid it
- You can mitigate it
- You can transfer it, and
- You can accept it.
In the case of scanner findings there is a fifth one which is: It’s a false positive, just ignore this.
Transferring for vulnerabilities works only somewhat, but it’s absolutely legitimate to accept a vulnerability. If you’re going to say “I cannot fix this vulnerability right now because the operating system does not get updated”, what are you going to do with it? You can keep alerting them but it’s not going to go anywhere.
Mitigation, of course, that’s what everyone wants to have.
But avoiding is also possible. You can just say: “I’m going to decommission this system next week I’m not going to fix this vulnerability. You can notify me all you want.”
In the end, please, if you build a such a program, please track that the engagement that your teams have with this program make sure that this is actually being used and make sure that it actually moves the needle.
Find some form of proxy, for example meantime to remediation or false positive rate, and make sure that you’re actually getting something out of this.
Well, we dove in head-first and we thought: “How difficult can it possibly be to build something like this?!”. The answer is: Very.

We started with different scanners competing for our attention and in the end there are tools that show weaknesses better than others. 10 different scanners that are not connected are typically not as good at showing weaknesses and you have to stitch them together manually – but then there are tools that actually do this really well. I’m not sure if you’ve heard the name CNAPP, cloud-native application protection platforms. Goes by different marketing names. Wiz is one of those tools, Orca is one of those tools, there is Palo Alto’s Prisma. There are different tools that you can use for this.
What the industry has started to realize is that attack path are more useful than CVEs. CVEs are potential risks but CVEs is more of kind of a thing that if you have the dependabot or renovate you’re good right. That’s the answer to most CVEs: Just patch your stuff. Attack paths are different: They represent how different CVEs and infrastructure misconfigurations can actually be stitched together. It’s still a theoretical inside-out view on your tech estate, so you’re not going to have the attacker prioritization for this, but it’s vastly more useful and has way more context to things that actually can go wrong in your tech estate. So attack paths are better than cves.
The next thing is: in your tool belt, there should be something that patrols the outside of your of your tech estate. We adopted Shodan and Tenable. Shodan is an port scanner and Tenable – I think most of you should be should be aware of the Nessus scanners – they scan the outside of our tech estate. If something gets found there that is exploitable, your SLA of how long do I have to fix this should actually drop to zero. Or like “this should have been fixed yesterday!”. So in that case, the 72 hours that most companies have are way too long. If you have an exploitable vulnerability, you have minutes or maybe hours, but definitely not more than 24 hours to fix this thing. So in that case, fix whatever is visible on the outside as soon as possible and ideally also conduct a threat hunt.
But no vulnerability management program is complete without offensive security efforts and at that point I’m going to hand over to Nazneen.

Nazneen
Thank you. As we worked on our security strategy, we understood that we had to evolve it from merely reacting to vulnerabilities. We decided not to wait for issues to arise but actively seek them out through offensive security practices. Only relying on passive scanning can give a false sense of security. These tools tend to create vulnerabilities alerts based on predefine signatures and algorithms. They often miss the nuances of how these vulnerabilities can be exploited in a real-world context, in the context of your organization. A few of us got got enthusiastic and curious to understand: “How do we really get to understand these vulnerabilities and how are they exploited in our context?”. So we proposed to start with an internal red team and of course without the right skills and without the priorities that did not go far. So then we propose let’s enhance our current vulnerability management process to understand what are the attack surfaces these scanners miss. And with that, we started focusing on active probing and we looked at ways to understand: How do we cover OIDC-based account takeovers? Authentication bypass vulnerabilities? Subdomain takeovers? Normally these are not found by scanners and it would get covered if we were not looking at it from an offensive security lens. In fact we went ahead to also understand what are the scanners that we can put in place to do active probing over the internet, to see what what what kind of internal data is available publicly. Or typo-squatting domains. So a few of us taking two hours in a week proposed this and then we went ahead to see now adding it to the top of the pyramid how can it benefit us. And and we were quite amazed by the benefits.
But apart from our team the delivery teams also appreciated it. When the delivery teams could see an attack actually happen in a controlled manner, they could appreciate why this vulnerability should be fixed or why the analysts are continuously following up. So, being able to give the teams a list of list of vulnerabilities based on not on a list of issues coming not from a scanner, but based on the potential of the exploit, and being able to be exploited, was helpful for the teams. So in in this case we never waited only for outside input, we worked with the team saying let’s work with the compromise credential and see where the impact is coming through. How are you able to exfiltrate data? How are we able to escalate privilege? And that is when they could see the need for layered defense, or as we say defense in depth. So overall it has been appreciated by the teams because we help them to make more informed decisions, reduce noise, but also increase the focus on critical issues that can hinder the security of the organization. Actually, one of the side effects for us is that we could also nicely see how our defenses are lined up against the MITRE Att&Ck framework work and it was a valuable bonus to us to get that visual too. I’m talking of the Att&Ck framework, so it’s like taking it as adversary but seeing where our defenses are lined up. So that was quite that was quite good.
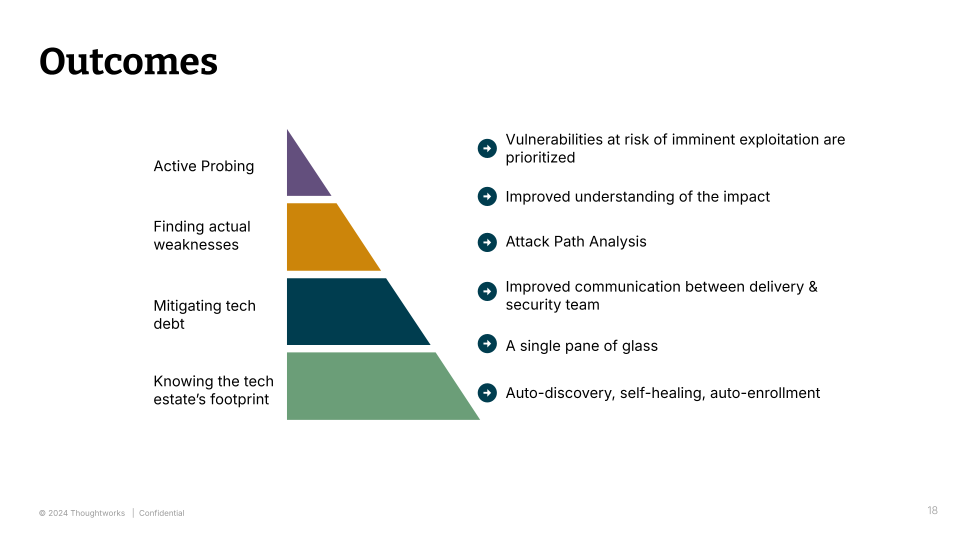
So, overall our overall our transformation work towards auto-discovery, self-healing, self-enrollment helped us understand our tech estate better, as well as scale with our scaling operations. We work towards reducing the cognitive load to look at various scanners by bringing a single pane of glass. We work towards improving the communication by working on a system that worked for the delivery teams, because they have to respond to the vulnerabilities. So make it easier for them. We prioritize attack path analysis, which helps the teams to understand the impact better. And with active probing we were able to help give the teams a list of prioritized vulnerabilities. And I guess yeah that’s a wrap.

Felix
Cool, so thank you for being with us. If there is nothing else that you want to take away, let it be these four points.
And with this: Thanks for spending the time with us, we’re ready to take our take your questions, and here is how to reach us over wherever you prefer to reach us. Thank you!